
7 фундаментальных технических SEO вопросов, на которые нужно ответить с помощью анализа логов (и как это легко сделать)
- Первое: выбор инструментов
- 1. Какие боты получают доступ к вашему сайту? Ищите спам-ботов или скребки, чтобы заблокировать.
- 2. Все ли ваши целевые роботы поисковой системы имеют доступ к вашим страницам?
- 3. Какие страницы не обслуживаются правильно? Найдите страницы с HTTP-статусами 3xx, 4xx и 5xx.
- 4. Какие страницы просматриваются каждым из поисковых роботов? Убедитесь, что они совпадают с наиболее...
- 5. Поисковые роботы сканируют страницы, которые они не должны?
- 6. Каков ваш показатель сканирования Googlebot с течением времени и как он соотносится со временем...
- 7. Какие IP-адреса Googlebot использует для сканирования вашего сайта? Убедитесь, что они правильно...
- Последние мысли
Анализ журнала развился, чтобы стать фундаментальной частью технического аудита SEO. Журналы сервера позволяют нам понять, как сканеры поисковых систем взаимодействуют с нашим веб-сайтом, и анализ журналов вашего сервера может привести к практическим выводам SEO, которые вы, возможно, не получили бы в противном случае.
Первое: выбор инструментов
Доступно множество инструментов для анализа журналов сервера, и какой из них вам подходит, зависит от ваших технических знаний и ресурсов. Существует три типа инструментов анализа файлов журналов, которые вы захотите рассмотреть (если вы не делаете это из командная строка , что я бы не советовал, если у вас еще нет опыта):
превосходить
Если вы знаете, как обходиться с Excel - если создание сводных таблиц и использование VLOOKUP для вас - вторая натура - вы можете попробовать Excel, выполнив шаги, показанные в это руководство от BuiltVisible ,
Также важно отметить, что даже если вы используете один из других параметров инструмента, в какой-то момент вам придется экспортировать данные, которые вы собрали, в Excel. Это выведет данные в формат, который легко интегрировать или сравнивать с другими источниками данных, такими как Google Analytics или Google Search Console.
Используете ли вы Excel на протяжении всего анализа или только в конце, будет зависеть от того, сколько времени вы хотите потратить, используя его для фильтрации, сегментации и организации данных.
Инструменты с открытым исходным кодом
Это ваш выбор, если у вас нет бюджета на инструменты, но у вас есть технические ресурсы для их настройки. Самым популярным вариантом с открытым исходным кодом является Elastic's Стек ELK , который включает в себя Kibana, Elasticsearch и Logstash.
Платные инструменты
Это действительно лучший вариант, если у вас нет технической поддержки или ресурсов, тем более что эти инструменты довольно просты в настройке. Несколько опций также поддерживают cURL на случай, если вам нужно вручную загрузить файлы журналов (вместо того, чтобы подключаться напрямую к серверу для мониторинга):
- Splunk вероятно, самый известный платный анализатор логов на рынке, хотя это и не самый дешевый вариант. Тем не менее, он имеет облегченная версия тот это бесплатно что вы можете проверить.
- Logz.io предлагает ELK в качестве услуги (она основана на облаке), рассмотрел SEO как один из их вариантов использования и имеет бесплатный вариант тоже.
- Loggly также имеет ограниченную бесплатную версию. Это тот, который я использую в данный момент, после того, как попробовал другие, и это программа, которую вы увидите на моих скриншотах на протяжении всего произведения. Loggly основан на облаке, и мне очень нравится его простой в использовании интерфейс, который облегчает фильтрацию и поиск. Эта функциональность позволяет мне сэкономить время на анализ, а не на сегментацию и фильтрацию данных.
Как только вы выбрали лучший инструмент для своего случая, пришло время начать с анализа. Вы захотите убедиться, что вы сосредоточили свой анализ на действенных SEO-элементах, так как легко потеряться в не-SEO-ориентированной среде.
Вот несколько вопросов, которые помогут мне провести анализ журнала, и как я могу легко на них ответить (используя Loggly, в моем случае). Я надеюсь, что это позволит вам увидеть, как вы можете просматривать свои журналы безболезненно и анализировать их для своего собственного процесса SEO.
1. Какие боты получают доступ к вашему сайту? Ищите спам-ботов или скребки, чтобы заблокировать.
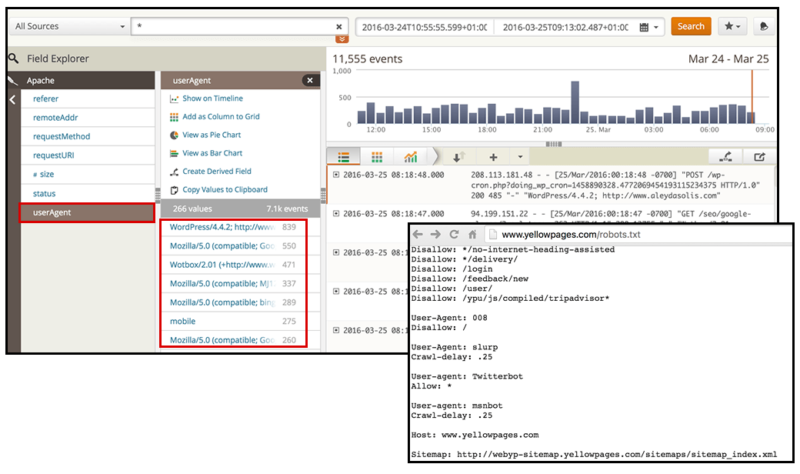
Логи следуют за предопределенный формат , Как вы можете видеть на снимке экрана ниже, идентификацию пользовательского агента можно сделать проще в Loggly с помощью предопределенных фильтров для полей журнала.
[Нажмите, чтобы увеличить]
Когда вы начинаете выполнять анализ журнала в первый раз, возможно, стоит не только проверить активность поисковых роботов (таких как Googlebots , bingbots или же Яндекс боты ), а также потенциальных спам-ботов, которые могут вызвать проблемы с производительностью, загрязнить аналитику и очистить ваш контент Для этого вы можете проверить перекрестную проверку со списком известных пользовательских агентов, такой как этот ,
Ищите подозрительных ботов, а затем анализируйте их поведение. Какова их активность с течением времени? Сколько событий у них было за выбранный период времени? Совпадает ли их появление с проблемами производительности или спама?
Если это так, вы можете не только запретить этих ботов в файле robots.txt, но и заблокировать их через htaccess , поскольку они не будут часто следовать директивам robots.txt.
2. Все ли ваши целевые роботы поисковой системы имеют доступ к вашим страницам?
После того, как вы определили ботов, которые приходят на ваш сайт, пришло время сосредоточиться на ботах поисковых систем, чтобы убедиться, что они успешно получают доступ к вашим страницам и ресурсам. С помощью фильтра «userAgent» в Loggly вы можете напрямую выбирать те, которые вы хотите проанализировать, или искать их по имени с помощью функциональность поиска с использованием логических операторов ,
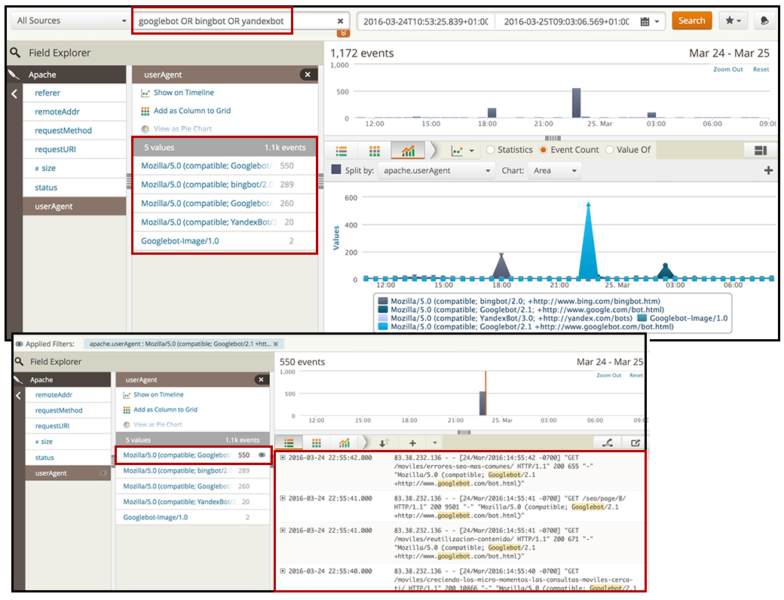
После того как вы отфильтруете показ только интересующих вас поисковых роботов, вы можете выбрать графическую опцию, чтобы визуализировать их активность с течением времени. Какие поисковые роботы имеют самый высокий уровень активности на вашем сайте? Они совпадают с поисковыми системами, которые вы хотите ранжировать?
Например, в этом случае мы можем видеть, что один из Google-ботов обладает вдвое большей активностью, чем один из Bing-ботов, и у него был определенный всплеск в 22:30 часов 24 марта.
[Нажмите, чтобы увеличить]
Здесь важно не только то, что поисковые роботы приходят на ваш сайт, но и то, что они тратят свое время на сканирование нужных страниц. Какие страницы они ползают? Каков статус HTTP этих страниц? Поисковые роботы сканируют одни и те же страницы или разные?
Вы можете выбрать каждого из поисковых пользовательских агентов, которые вы хотите проверить, и экспортировать данные, чтобы сравнить их, используя сводные таблицы в Excel:
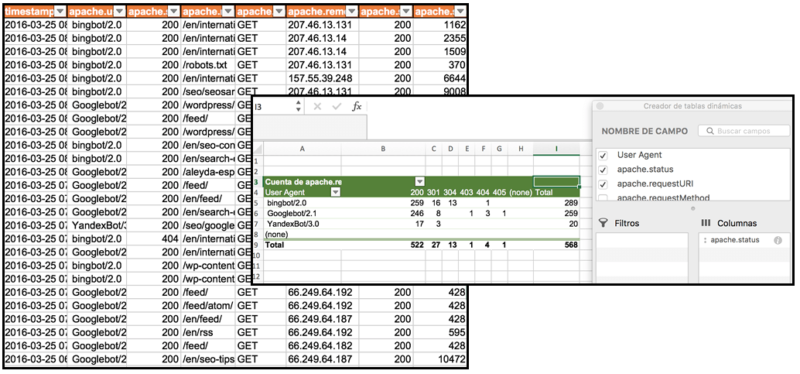
Основываясь на этой исходной информации, мы начнем копать глубже, чтобы проверить не только, как эти боты различаются в поведении сканирования, но и действительно ли они сканируют, где они должны быть.
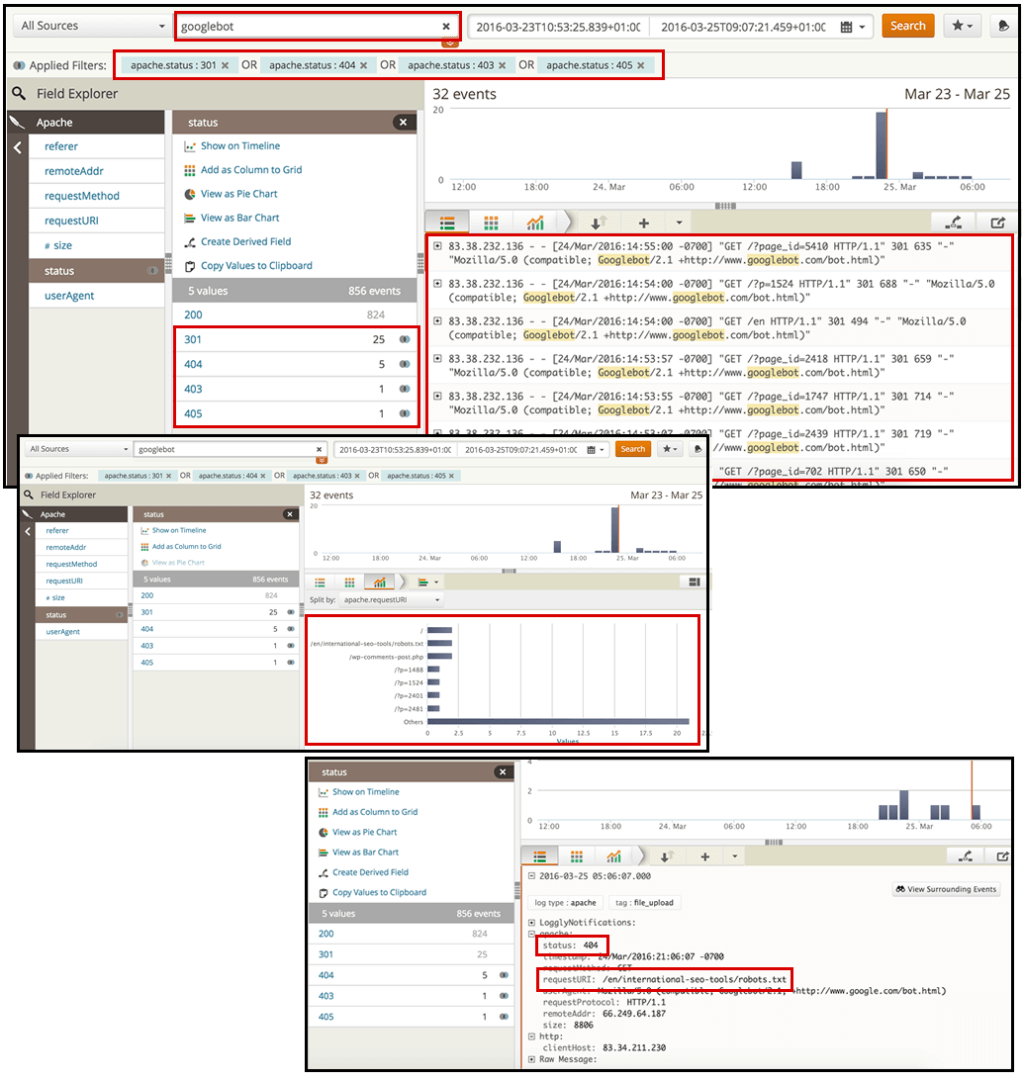
3. Какие страницы не обслуживаются правильно? Найдите страницы с HTTP-статусами 3xx, 4xx и 5xx.
Выполнив поиск нужного поискового бота (в данном случае Googlebot), а затем выбрав фильтр «статус», вы можете выбрать значения HTTP для страниц, которые вы хотите проанализировать.
Я рекомендую искать те с кодами состояния 3xx, 4xx и 5xx, поскольку вы хотите видеть перенаправленные страницы или страницы ошибок, которые вы отправляете сканерам.
[Нажмите, чтобы увеличить]
Отсюда вы можете определить главные страницы, генерирующие большинство перенаправлений или ошибок. Вы можете экспортировать данные и расставить приоритеты для этих страниц, чтобы это было исправлено в ваших рекомендациях по SEO.
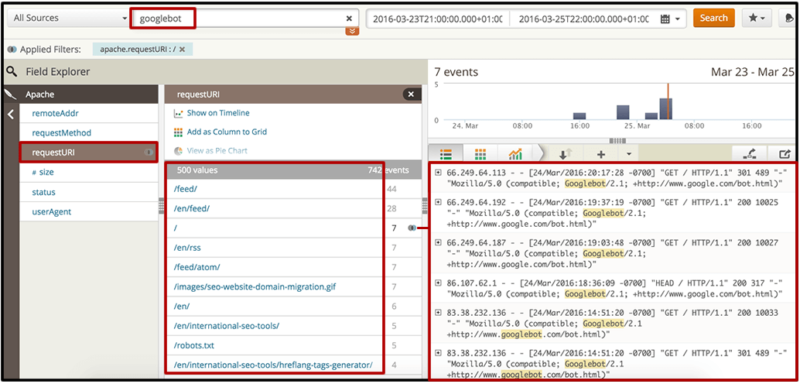
4. Какие страницы просматриваются каждым из поисковых роботов? Убедитесь, что они совпадают с наиболее важными для вашего сайта.
При поиске нужного поискового бота вы можете напрямую выбрать фильтр «requestURI», чтобы получить список самых популярных веб-документов, будь то ресурсы или страницы, которые запрашивает бот. Вы можете просмотреть их непосредственно в интерфейсе (например, чтобы убедиться, что они имеют статус HTTP 200) или экспортировать их в документ Excel, где вы можете определить, совпадают ли они с вашими приоритетными страницами.
[Нажмите, чтобы увеличить]
Если ваши самые важные страницы не входят в число наиболее популярных страниц (или, что еще хуже, вообще не включены), вы можете выбрать соответствующие действия в своих рекомендациях по SEO. Возможно, вы захотите улучшить внутренние ссылки на эти страницы (будь то с домашней страницы или с некоторых из выявленных вами страниц с наибольшим количеством просканированных страниц), а затем сгенерировать и отправить новую карту сайта XML.
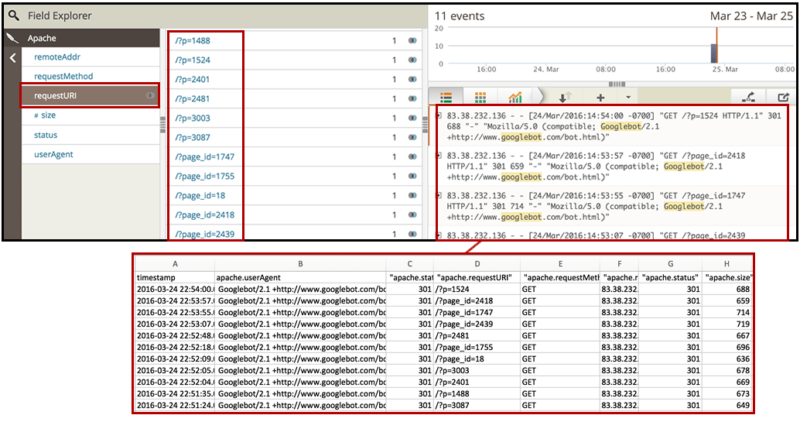
5. Поисковые роботы сканируют страницы, которые они не должны?
Вы также захотите идентифицировать страницы и ресурсы, которые не предназначены для индексации и, следовательно, не должны сканироваться.
Снова используйте фильтр «requestURI», чтобы получить список самых запрашиваемых страниц по вашему желаемому боту, а затем экспортируйте данные. Проверьте, действительно ли просматриваются страницы и каталоги, заблокированные вами через robots.txt.
[Нажмите, чтобы увеличить]
Вы также можете проверить страницы, которые не заблокированы через robots.txt, но не должны иметь приоритетов с точки зрения сканирования - это включает в себя страницы, которые не индексируются, канонизируются или перенаправляются на другие страницы.
Для этого вы можете выполнить обход списка из экспортированного списка с помощью вашего любимого сканера SEO (например, Screaming Frog или OnPage.org), чтобы добавить дополнительную информацию об их статусе мета-роботов: отсутствие индексации и статус канонизации, в дополнение к статусу HTTP, который вы уже будет из логов.
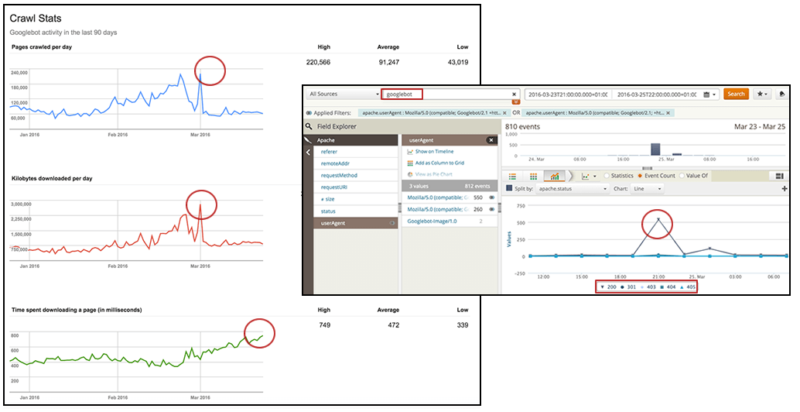
6. Каков ваш показатель сканирования Googlebot с течением времени и как он соотносится со временем ответа и количеством страниц с ошибками?
К сожалению, данные, которые можно получить с помощью отчета «Статистика сканирования» в Google Search Console, являются слишком общими (и не обязательно достаточно точными), чтобы принять меры. Таким образом, анализируя ваши собственные журналы, чтобы определить частоту сканирования роботом Google с течением времени, вы можете проверить информацию и сегментировать ее, чтобы сделать ее действующей.
С Loggly вы можете выбрать просмотр активности робота Googlebot в желаемом временном диапазоне на линейном графике, где статус HTTP может отображаться независимо, чтобы проверить всплески во времени. Знание того, какой тип HTTP-запросов произошел и когда, покажет, были ли вызваны ошибки или перенаправления, что может привести к неэффективному поведению при сканировании роботом Google.
[Нажмите, чтобы увеличить]
Вы можете сделать что-то подобное, составив график размера файлов, запрашиваемых роботом Google, в течение требуемого периода времени, чтобы определить, есть ли корреляция с изменениями поведения при сканировании, а затем вы можете предпринять соответствующие действия для их оптимизации.
7. Какие IP-адреса Googlebot использует для сканирования вашего сайта? Убедитесь, что они правильно обращаются к соответствующим страницам и ресурсам в каждом случае.
Я включил его специально для веб-сайтов, которые предоставляют разный контент пользователям в разных местах. В некоторых случаях такие веб-сайты по незнанию предоставляют сканерам с IP-адресами из других стран плохой опыт - от прямой блокировки до предоставления им доступа только к одной версии контента (не позволяя сканировать другие версии).
Google теперь поддерживает сканирование с учетом локали обнаруживать контент, специально предназначенный для других стран, но все равно рекомендуется убедиться, что весь ваш контент сканируется. Если нет, это может указывать на то, что ваш сайт настроен неправильно.
После сегментации по пользовательскому агенту вы можете выполнить фильтрацию по IP, чтобы убедиться, что сайт предоставляет правильную версию каждой страницы сканерам из соответствующих стран.
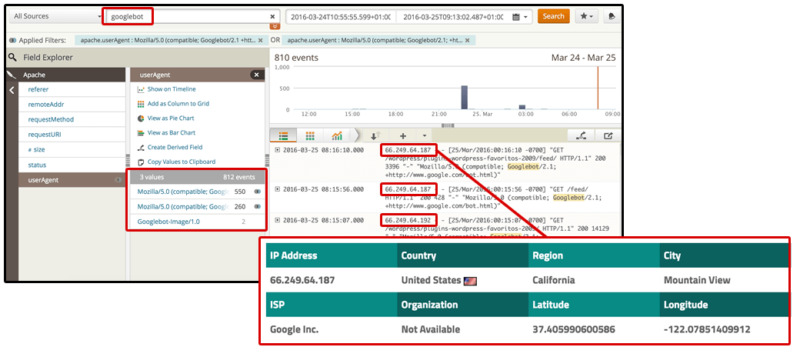
[Нажмите, чтобы увеличить]
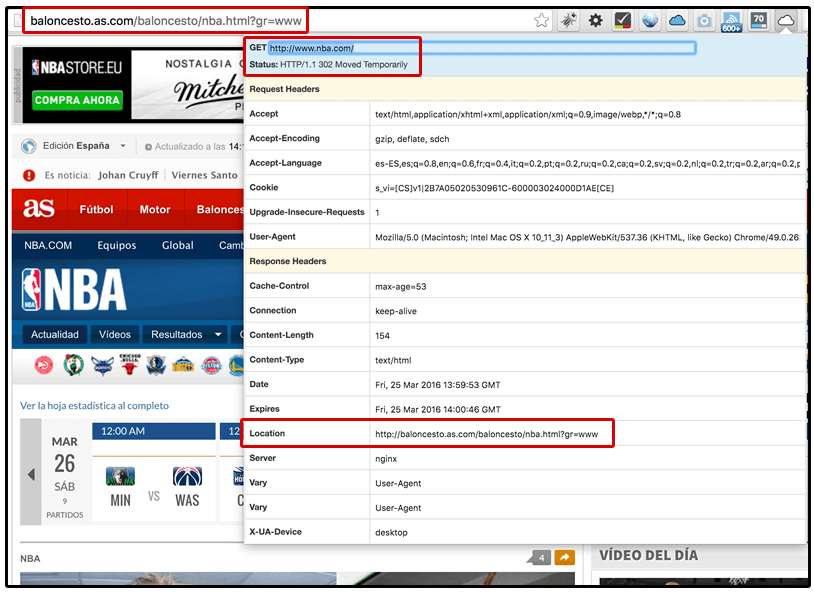
Например, посмотрите, что происходит, когда я пытаюсь получить доступ к сайту NBA по адресу www.nba.com с испанским IP-адресом. Я 302 перенаправлен на поддомен о баскетболе с сайта AS (местной спортивной газеты в Испании). , как видно на скриншоте ниже.
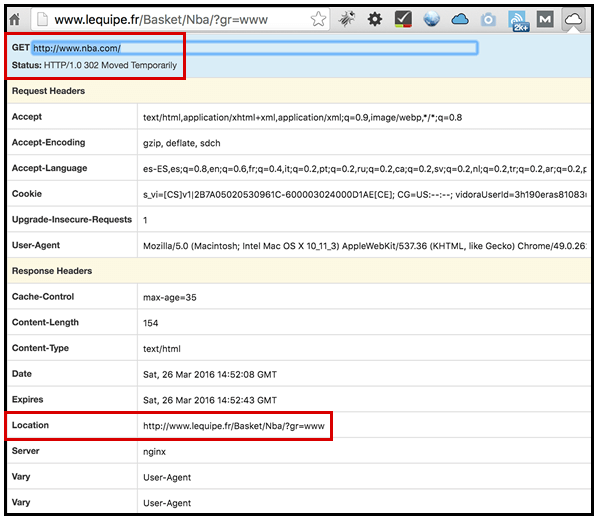
Нечто подобное происходит, когда я вхожу с французского IP; Я получаю 302, перенаправленную в баскетбольную подкаталогу местной спортивной газеты L'Equipe во Франции.
Я объяснил в прошлом, почему Я не фанат международных целевых автоматических перенаправлений , Однако, если они предназначены для существования по деловым (или любым другим) причинам, важно обеспечить единообразное поведение всех сканеров, прибывающих из одной и той же страны - поисковых роботов и любых других пользовательских агентов - чтобы убедиться, что лучшие практики SEO следовал в каждом случае.
Последние мысли
Я надеюсь, что ответы на эти вопросы и объяснение того, как на них можно ответить с помощью анализа логов, помогут вам расширить и усилить ваши технические усилия по SEO.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Похожие
Что такое SEO? Как это работает?Что такое SEO? SEO, или поисковая оптимизация, относится к процессу получения «бесплатного», «органического» или «естественного» трафика веб-сайта через результаты поиска поисковых систем, таких как Google, Bing и Yahoo. Например, если вы будете искать определенное ключевое слово в Поиске Google, ваш сайт будет указан на странице результатов поисковой системы в заданной Как работает SEO маркетинг?
... онимаю, что вам нужно быть хладнокровным, чтобы дать правильную карту. Прежде чем начать еще один пример, я должен поблагодарить вас за доверие к моей работе. Без вашего присутствия здесь этот канал не был бы таким, какой он есть! Итак, спасибо! Вы готовы начать? Давай! SEO маркетинг - что это такое и как это работает? Вы можете найти заголовок содержащий Joomla SEO
... ие SEO расширения Joomla могут помочь вам повысить рейтинг"> Какие SEO расширения Joomla могут помочь вам повысить рейтинг? Joomla - одна из наиболее популярных систем управления контентом или CMS. Если вы выбираете Joomla чтобы создать свой сайт, важно использовать правильные расширения. Расширение - это еще один способ сказать плагин, и с Joomla вы будете использовать расширения. Одним из наиболее важных SEO стажер
Как Инфотех является профессионально ориентированной компанией веб-дизайна и веб-разработки, расположенной в Нью-Дели, Индия. Мы проводим обучение по проектам в области поисковой оптимизации в режиме реального времени для выпускников ИТ-отделов / Fresher, которые готовы сделать свою карьеру Как Пингвин 4.0 изменил SEO
... связи с тем, что последнее обновление Google Penguin 4.0 было выпущено сравнительно недавно, многие эксперты по SEO и разработчики веб-контента хотят знать, какое влияние это изменение алгоритма, которое было реализовано 23 сентября 2016 года, окажет на их онлайн-активность в будущем. Ниже приведены некоторые из изменений, которые вы можете ожидать увидеть в ближайшие несколько месяцев. Штрафы могут быть практически мгновенными В тот момент, когда Google сканирует BruceClay - Как сделать SEO Конкурентный анализ
... какие сайты являются вашими основными конкурс ключевых слов , Далее вы сыграете в детектив и познакомитесь с этими первоклассными сайтами. Вот что нужно искать, когда вы делаете SEO конкурентный анализ: Ключевые слова: для каких других ключевых слов оптимизирована конкурирующая веб-страница? Контент. Сколько контента имеется для ключевого слова, на которое Мощные методы поисковой оптимизации, которые вы должны использовать
... они ищут место для следующего путешествия, они могут просто выполнить простой поиск по указанным сайтам. Пользователи онлайн часто нажимают на веб-сайты, которые находятся на вершине. Чем выше рейтинг, тем больше шансов получить больше трафика. Предприятия должны стремиться к верхней позиции, чтобы больше людей могли просматривать их веб-сайт. Поисковая оптимизация или SEO помогают сайтам улучшить свой поисковый рейтинг. Изучите методы, чтобы подняться вверх по лестнице поисковой системы. White Hat SEO - Position1SEO
... инственной возможностью, когда вы думаете об оптимизации вашего сайта"> SEO является единственной возможностью, когда вы думаете об оптимизации вашего сайта. Возможно, в прошлом вы откладывали SEO, неохотно заполняя свой сайт скрытым текстом и обратными ссылками. К счастью, эти методы являются пережитками прошлого. Благодаря обновлениям Google, таким как Caffeine, Panda и Penguin, призванным обеспечить, чтобы Google предоставлял своим пользователям только полезные релевантные веб-сайты, Сделай сам SEO: Nine0Media (858) 212-3690
Nine0Media - это все в одном SEO Консалтинг компания в Сан-Диего. Добро пожаловать в Nine0Media «Сделай сам план SEO». DIY SEO идеально подходит для малого бизнеса с ограниченным бюджетом на SEO и управление социальными медиа. Научитесь выполнять основные Как проводить SEO исследования конкурентов с помощью Excel
... скажет вам, что трудная часть работы заключается не только в том, чтобы работать самостоятельно, но и в том, чтобы следить за тем, что делают ваши конкуренты. Имея это в виду, вот способ, которым вы можете проводить обычные исследования конкурентов для своего SEO, используя только электронную таблицу Microsoft Excel! Наше решение отправляется в Google и возвращает лучшие результаты по поисковому запросу. Почему это важно? Это полезно, если вы хотите знать, кто ваши Что такое поисковая оптимизация (SEO)?
... какие ключевые слова и ключевые фразы демонстрируют наибольший потенциал и с большей вероятностью помогут вашему сайту привлечь более целевой трафик. Но, как всегда, вам нужно иметь соответствующий термин для поискового запроса пользователя. При выполнении KEI вы, вероятно, ищете не ключевые слова, а ключевые фразы. Самая важная ключевая фраза - это та, которая описывает содержание вашей конкретной веб-страницы. Давайте еще раз посмотрим на наш практический
Комментарии
Какие страницы не обслуживаются правильно?Какие страницы не обслуживаются правильно? Ищите страницы с HTTP-статусами 3xx, 4xx и 5xx И многое другое! 3. Узнайте, переключился ли ваш сайт на индекс Google для мобильных устройств. Вы также можете использовать журналы сервера сайта, чтобы узнать, получает ли ваш сайт повышенный просмотр с помощью смартфона Googlebot для смартфона, указывая, что он был переключен на Индекс мобильной связи , И снова, SEO - это аргумент, который иногда игнорируется среди нас, разработчиков, но все это восходит к мысли, что если никто не может найти ваш сайт, какое это имеет значение?
И снова, SEO - это аргумент, который иногда игнорируется среди нас, разработчиков, но все это восходит к мысли, что если никто не может найти ваш сайт, какое это имеет значение? Человек может сказать «не я», но как они работают оптимально как в краткосрочной, так и в долгосрочной перспективе, если они никогда не работают вблизи пределов или порогов?
Человек может сказать «не я», но как они работают оптимально как в краткосрочной, так и в долгосрочной перспективе, если они никогда не работают вблизи пределов или порогов? Но теперь, когда Google начал активно наказывать сайты за неестественные профили ссылок и ужесточать эти пороги, конкуренты подталкивали друг друга. Некоторые из наиболее широко освещаемых примеров дурацкого SEO были не попытками SEO, а преднамеренным конкурентным саботажем . Почему многие Вам нужно только протестировать базовую скорость вашего сайта, или вы хотите получить подробные советы о том, как именно повысить скорость вашего сайта?
Вам нужно только протестировать базовую скорость вашего сайта, или вы хотите получить подробные советы о том, как именно повысить скорость вашего сайта? Это определит, какие инструменты могут быть лучше для вас. PageSpeed Insights Если вы ищете бесплатный, простой в использовании инструмент, который может оценить скорость вашего сайта, Прямо сейчас вы, возможно, спросите, как это влияет на поисковые системы, такие как Google, каков URL страницы?
Прямо сейчас вы, возможно, спросите, как это влияет на поисковые системы, такие как Google, каков URL страницы? Наверняка компьютеру все равно? Ну, вы были бы в некотором роде правы, но дело в том, что наличие ключевых слов, по которым вы пытаетесь ранжироваться в URL страницы, действительно имеет значение. Есть много вещей, которые играют роль в том, как Google определяет рейтинг веб-страницы, и никто не может точно сказать, насколько большую роль играет каждый из этих факторов. Однако SEO маркетинг - что это такое и как это работает?
SEO маркетинг - что это такое и как это работает? Вы можете найти заголовок содержащий два вопроса, не так ли? Если вы следили за этим каналом в течение некоторого времени, вы, должно быть, поняли, что мне всегда нравится объяснять и разделять тексты. Тем не менее, чтобы более четко следовать цели этой статьи, я не видел другой возможности объяснить вам, как работает SEO-маркетинг, не объяснив, С точки зрения SEO, этот выбор включает стратегический выбор - где мы должны поместить силу (авторитет) контента в глазах поисковых систем - на страницах сайта или во внешнем файле (PDF)?
С точки зрения SEO, этот выбор включает стратегический выбор - где мы должны поместить силу (авторитет) контента в глазах поисковых систем - на страницах сайта или во внешнем файле (PDF)? Хотя существуют ситуации, требующие использования обоих форматов, и, хотя PDF-файлы обычно хорошо индексируются и принимаются поисковыми системами, выбор PDF-файла имеет несколько недостатков. Прежде всего, важно понимать, что, когда пользователь переходит непосредственно от результатов Заметили ли вы, что, несмотря на это, SEO вашего сайта не улучшается?
Заметили ли вы, что, несмотря на это, SEO вашего сайта не улучшается? Время пришло: оптимизировать SEO в вашем WordPress. В чем основная проблема? Дублированный контент, который нам часто дает такая большая война, помимо того, что является основной проблемой, также является наиболее распространенным среди веб-страниц, созданных с помощью WordPress. Наличие нескольких страниц, которые говорят об одном и том же, является наиболее Есть ли регулярный новый контент и настолько ли он интересен, что другие страницы ссылаются на ваши сообщения?
Есть ли регулярный новый контент и настолько ли он интересен, что другие страницы ссылаются на ваши сообщения? Мы рады сотрудничать с вами, чтобы разработать концепцию оптимизации контента вашего сайта. Предоставьте своим клиентам соответствующую информацию, практическую помощь и целевую поддержку. Наши профессионалы в области SEO обладают опытом создания лучшего контента и способностью оказывать редакционную поддержку. Оптимизация на странице и вне страницы - что это? Разве не много технических вопросов, на которые нужно ответить?
Разве не много технических вопросов, на которые нужно ответить? URL и архитектура сайта, чтобы думать о? Это правда, есть много очень технический Компоненты, которые следует учитывать при хорошем ранжировании в поисковых системах, но самая последняя тенденция заключалась в том, чтобы не поощрять тех, кто пытается получить рейтинг Мы знаем, что страницы с ошибками предлагают явно отрицательный пользовательский опыт, но как они влияют на поисковые системы?
Мы знаем, что страницы с ошибками предлагают явно отрицательный пользовательский опыт, но как они влияют на поисковые системы? 404 страницы вредны для SEO ? Штрафуют ли поисковые системы сайты, содержащие слишком много 404 кодовых страниц статуса? В этой статье я рассмотрю страницы ошибок 404 с точки зрения пользователей и поисковых систем и порекомендую некоторые из лучших практик, которые можно использовать, чтобы улучшить свои
1. Какие боты получают доступ к вашему сайту?
2. Все ли ваши целевые роботы поисковой системы имеют доступ к вашим страницам?
3. Какие страницы не обслуживаются правильно?
4. Какие страницы просматриваются каждым из поисковых роботов?
5. Поисковые роботы сканируют страницы, которые они не должны?
7. Какие IP-адреса Googlebot использует для сканирования вашего сайта?
1. Какие боты получают доступ к вашему сайту?
Какова их активность с течением времени?
Сколько событий у них было за выбранный период времени?
Совпадает ли их появление с проблемами производительности или спама?