
Ultimate Robots.txt Руководство по повышению эффективности сканирования
- Robots.txt вкратце Файл robots.txt содержит директивы для поисковых систем, которые вы можете использовать,...
- Терминология вокруг файла robots.txt
- Почему вы должны заботиться о файле robots.txt?
- пример
- Ваш robots.txt работает против вас?
- Пользовательский агент в robots.txt
- Запретить в robots.txt
- пример
- Разрешить в robots.txt
- пример
- Пример конфликтующих директив
- Отдельная строка для каждой директивы
- Использование подстановочного знака *
- пример
- Используя конец URL $
- пример
- Карта сайта в robots.txt
- Примеры
- Пример 1
- Пример 2
- Задержка сканирования в robots.txt
- Пример:
- Когда использовать файл robots.txt?
- Лучшие практики для файла robots.txt
- Порядок приоритета
- пример
- пример
- Только одна группа директив на одного робота
- Будьте максимально конкретны
- Пример:
- Директивы для всех роботов, а также директивы для конкретного робота
- пример
- Файл Robots.txt для каждого (под) домена
- Примеры
- Противоречивые рекомендации: robots.txt против Google Search Console
- Следите за своим файлом robots.txt
- Как вы узнаете, когда ваш robots.txt изменится?
- Не используйте noindex в вашем robots.txt
- Примеры файла robots.txt
- Все роботы могут получить доступ ко всему
- Все роботы не имеют доступа
- Все боты Google не имеют доступа
- Все боты Google, кроме новостей Googlebot, не имеют доступа
- Googlebot и Slurp не имеют доступа
- Все роботы не имеют доступа к двум каталогам
- Все роботы не имеют доступа к одному конкретному файлу
- Робот Google не имеет доступа к / admin /, а Slurp не имеет доступа к / private /
- Robots.txt для WordPress
- Каковы ограничения файла robots.txt?
- Страницы, все еще появляющиеся в результатах поиска
- Кэширование
- Размер файла
- Часто задаваемые вопросы о robots.txt
- 2. Должен ли я быть осторожен с использованием файла robots.txt?
- 3. Является ли незаконным игнорирование файла robots.txt при очистке веб-сайта?
- 4. У меня нет файла robots.txt. Будут ли поисковые системы сканировать мой сайт?
- 5. Могу ли я использовать Noindex вместо Disallow в моем файле robots.txt?
- 6. Какие поисковые системы уважают файл robots.txt?
- 7. Как я могу запретить поисковым системам индексировать страницы результатов поиска на моем сайте WordPress?
Robots.txt вкратце
Файл robots.txt содержит директивы для поисковых систем, которые вы можете использовать, чтобы запретить поисковым системам сканировать определенные части вашего сайта.
При реализации robots.txt следует учитывать следующие рекомендации:
- Будьте осторожны при внесении изменений в ваш файл robots.txt: этот файл может сделать большие части вашего сайта недоступными для поисковых систем.
- Файл robots.txt должен находиться в корне вашего сайта (например, http://www.example.com/robots.txt).
- Файл robots.txt действителен только для всего домена, в котором он находится, включая протокол (http или https).
- Различные поисковые системы по-разному интерпретируют директивы. По умолчанию первая соответствующая директива всегда побеждает. Но, с Google и Bing, специфика выигрывает.
- По возможности избегайте использования директивы crawl-delay для поисковых систем.
Что такое файл robots.txt?
Файл robots.txt сообщает поисковым системам правила вашего сайта.
Поисковые системы регулярно проверяют файл robots.txt на веб-сайте, чтобы узнать, есть ли какие-либо инструкции по сканированию веб-сайта. Мы называем эти инструкции «директивами».
Если файл robots.txt отсутствует или отсутствуют соответствующие директивы, поисковые системы будут сканировать весь веб-сайт.
Хотя все основные поисковые системы уважают файл robots.txt, поисковые системы могут игнорировать (части) ваш файл robots.txt. Хотя директивы в файле robots.txt являются сильным сигналом для поисковых систем, важно помнить, что файл robots.txt представляет собой набор необязательных директив для поисковых систем, а не мандат.
Терминология вокруг файла robots.txt
Файл robots.txt является реализацией стандарта исключения роботов или также называется протоколом исключения роботов .
Почему вы должны заботиться о файле robots.txt?
Файл robots.txt играет важную роль с точки зрения поисковой оптимизации (SEO). Он сообщает поисковым системам, как лучше всего сканировать ваш сайт.
Используя файл robots.txt, вы можете запретить поисковым системам доступ к определенным частям вашего сайта , предотвратить дублирование контента и дать поисковым системам полезные советы о том, как они могут более эффективно сканировать ваш сайт.
Будьте осторожны при внесении изменений в ваш файл robots.txt: этот файл может сделать большие части вашего сайта недоступными для поисковых систем.
пример
Давайте посмотрим на пример, чтобы проиллюстрировать это:
Вы работаете на сайте электронной коммерции, и посетители могут использовать фильтр для быстрого поиска по вашим продуктам. Этот фильтр генерирует страницы, которые в основном показывают тот же контент, что и другие страницы. Это прекрасно работает для пользователей, но смущает поисковые системы, потому что это создает дублированный контент , Вы не хотите, чтобы поисковые системы индексировали эти отфильтрованные страницы и тратили свое драгоценное время на эти URL с отфильтрованным контентом. Поэтому вы должны установить правила Disallow, чтобы поисковые системы не обращались к этим фильтрованным страницам товаров.
Предотвращение дублирования контента также может быть сделано с помощью канонический URL или мета-тег роботов, однако они не позволяют поисковым системам сканировать только важные страницы. Использование канонического URL-адреса или метатега не помешает поисковым системам сканировать эти страницы . Это только запретит поисковым системам показывать эти страницы в результатах поиска . Так как поисковые системы ограничить время сканирования сайта , это время следует потратить на страницы, которые вы хотите отображать в поисковых системах.
Ваш robots.txt работает против вас?
Неправильно настроенный файл robots.txt может сдерживать вашу производительность SEO. Проверьте, так ли это для вашего сайта прямо сейчас!
Пример того, как может выглядеть простой файл robots.txt для веб-сайта WordPress:
Пользовательский агент: * Disallow: / wp-admin /
Давайте объясним анатомию файла robots.txt на основе приведенного выше примера:
- Пользовательский агент: пользовательский агент указывает, для каких поисковых систем предназначены следующие директивы.
- *: это указывает на то, что директивы предназначены для всех поисковых систем.
- Disallow: это директива, указывающая, какой контент недоступен для агента пользователя.
- / wp-admin /: это путь, недоступный для агента пользователя.
В итоге: этот файл robots.txt сообщает всем поисковым системам не входить в каталог / wp-admin /.
Пользовательский агент в robots.txt
Каждый поисковик должен идентифицировать себя с пользовательским агентом. Роботы Google идентифицируются как Googlebot, например, роботы Yahoo как Slurp, а робот Bing как BingBot и так далее.
Запись user-agent определяет начало группы директив. Все директивы между первым пользовательским агентом и следующей записью пользовательского агента обрабатываются как директивы для первого пользовательского агента.
Директивы могут применяться к конкретным пользовательским агентам, но они также могут применяться ко всем пользовательским агентам. В этом случае используется подстановочный знак: User-agent: *.
Запретить в robots.txt
Вы можете запретить поисковым системам доступ к определенным файлам, страницам или разделам вашего сайта. Это делается с помощью директивы Disallow. За директивой Disallow следует путь, к которому нельзя обращаться. Если путь не определен, директива игнорируется.
пример
Пользовательский агент: * Disallow: / wp-admin /
В этом примере всем поисковым системам запрещается доступ к каталогу / wp-admin /.
Разрешить в robots.txt
Директива Allow используется для противодействия директиве Disallow. Директива Allow поддерживается Google и Bing. Используя вместе директивы Allow и Disallow, вы можете сообщить поисковым системам, что они могут получить доступ к определенному файлу или странице в каталоге, который иначе запрещен. За директивой Allow следует путь, по которому можно получить доступ. Если путь не определен, директива игнорируется.
пример
Пользователь-агент: * Разрешить: /media/terms-and-conditions.pdf Запретить: / media /
В приведенном выше примере всем поисковым системам не разрешен доступ к каталогу / media /, за исключением файла /media/terms-and-conditions.pdf.
Важно: при совместном использовании директив Allow и Disallow не используйте подстановочные знаки, так как это может привести к конфликту директив.
Пример конфликтующих директив
User-agent: * Разрешить: / directory Disallow: /*.html
Поисковые системы не будут знать, что делать с URL http://www.domain.com/directory.html. Им неясно, разрешен ли им доступ.
Отдельная строка для каждой директивы
Каждая директива должна быть в отдельной строке, иначе поисковые системы могут запутаться при разборе файла robots.txt.
Пример неверного файла robots.txt
Запретите файл robots.txt следующим образом:
Агент пользователя: * Disallow: / directory-1 / Disallow: / directory-2 / Disallow: / directory-3 /
Использование подстановочного знака *
Подстановочный знак может быть использован не только для определения пользовательского агента, но и для сопоставления URL-адресов. Подстановочный знак поддерживается Google, Bing, Yahoo и Ask.
пример
Агент пользователя: * Disallow: / *?
В приведенном выше примере всем поисковым системам запрещен доступ к URL-адресам, на которых есть знак вопроса (?).
Используя конец URL $
Чтобы указать конец URL, вы можете использовать знак доллара ($) в конце пути.
пример
Пользователь-агент: * Disallow: /*.php$
В приведенном выше примере поисковым системам не разрешен доступ ко всем URL, которые заканчиваются на .php. URL-адреса с параметрами, например https://example.com/page.php?lang=en, не будут запрещены, так как URL не заканчивается после .php.
Карта сайта в robots.txt
Несмотря на то, что файл robots.txt был изобретен для того, чтобы сообщать поисковым системам, какие страницы не сканировать , файл robots.txt также можно использовать для указания поисковых систем на карту сайта XML. Это поддерживается Google, Bing, Yahoo и Ask.
Карта сайта XML должна указываться как абсолютный URL. URL-адрес не обязательно должен быть на том же хосте, что и файл robots.txt. Ссылка на карту сайта XML в файле robots.txt является одним из лучших советов, которые мы советуем вам всегда делать, даже если вы уже отправили карту сайта XML в Google Search Console или в Bing Webmaster Tools. Помните, что есть больше поисковых систем.
Обратите внимание, что в файле robots.txt можно ссылаться на несколько XML-файлов Sitemap.
Примеры
Несколько XML-файлов Sitemap:
Пользовательский агент: * Disallow: / wp-admin / Карта сайта: https://www.example.com/sitemap1.xml Карта сайта: https://www.example.com/sitemap2.xml
В приведенном выше примере всем поисковым системам запрещается обращаться к каталогу / wp-admin / и что есть два файла XML-карт, которые можно найти по адресу https://www.example.com/sitemap1.xml и https: //www.example. .com / sitemap2.xml.
Единая карта сайта XML:
Пользовательский агент: * Disallow: / wp-admin / Карта сайта: https://www.example.com/sitemap_index.xml
В приведенном выше примере всем поисковым системам запрещается обращаться к каталогу / wp-admin / и что карту сайта XML можно найти по адресу https://www.example.com/sitemap_index.xml.
Комментариям предшествует знак #, и они могут быть помещены либо в начале строки, либо после директивы в той же строке. Все после # будет игнорироваться. Эти комментарии предназначены только для людей.
Пример 1
# Не разрешать доступ к каталогу / wp-admin / для всех роботов. Пользовательский агент: * Disallow: / wp-admin /
Пример 2
User-agent: * # Относится ко всем роботам Disallow: / wp-admin / # Не разрешать доступ к каталогу / wp-admin /.
Приведенные выше примеры сообщают то же самое.
Задержка сканирования в robots.txt
Директива Crawl-delay является неофициальной директивой, используемой для предотвращения перегрузки серверов слишком большим количеством запросов. Если поисковые системы могут перегружать сервер, добавление Crawl-delay в ваш файл robots.txt является временным исправлением. Дело в том, что ваш сайт работает в плохой среде хостинга, и вы должны исправить это как можно скорее.
То, как поисковые системы обрабатывают задержку сканирования, отличается. Ниже мы объясним, как основные поисковые системы справляются с этим.
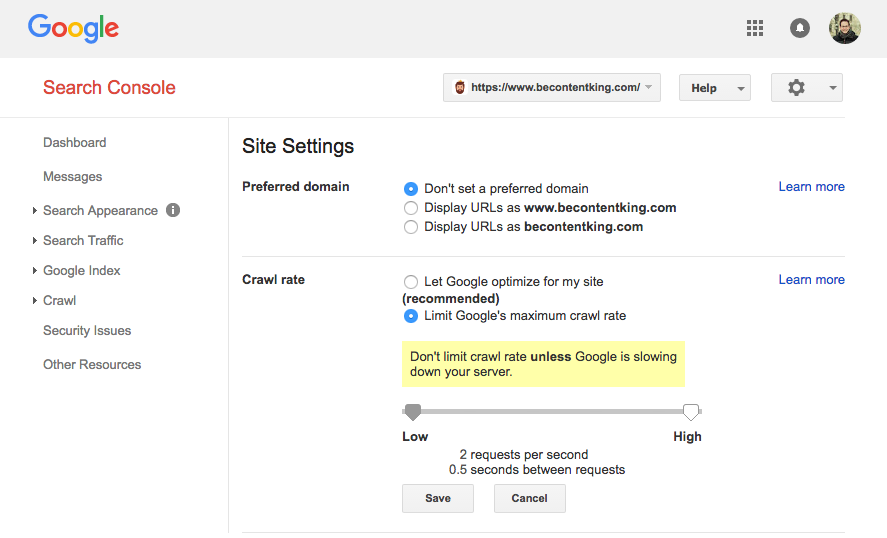
Google не поддерживает директиву Crawl-delay. Однако Google поддерживает определение скорости сканирования в Google Search Console. Следуйте инструкциям ниже, чтобы установить его:
- Войдите в консоль поиска Google.
- Выберите веб-сайт, для которого вы хотите определить скорость сканирования.
- Нажмите на значок шестеренки в правом верхнем углу и выберите «Настройки сайта».
- Существует опция «Скорость сканирования» с ползунком, с помощью которой вы можете установить предпочтительную скорость сканирования. По умолчанию для скорости сканирования установлено значение «Разрешить Google оптимизировать для моего сайта (рекомендуется)».
Бинг, Yahoo и Яндекс
Bing, Yahoo и Yandex поддерживают директиву Crawl-delay для ограничения сканирования сайта. Их интерпретация задержки сканирования отличается, поэтому не забудьте проверить их документацию:
Директива Crawl-delay должна быть размещена сразу после директив Disallow или Allow.
Пример:
Агент пользователя: BingBot Disallow: / private / Crawl-delay: 10
Baidu
Baidu не поддерживает директиву задержки сканирования, однако можно зарегистрировать учетную запись Baidu для веб-мастеров, в которой вы можете контролировать частоту сканирования, аналогично Google Search Console.
Когда использовать файл robots.txt?
Мы рекомендуем всегда использовать файл robots.txt. Нет ничего плохого в том, чтобы иметь его, и это отличное место, чтобы передать директивы поисковых систем о том, как они могут наилучшим образом сканировать ваш сайт.
Лучшие практики для файла robots.txt
Лучшие практики для файлов robots.txt подразделяются на следующие категории:
Файл robots.txt всегда должен размещаться в корне веб-сайта (в каталоге верхнего уровня хоста) и содержать имя файла robots.txt, например: https://www.example.com/robots.txt. , Обратите внимание, что URL-адрес файла robots.txt, как и любой другой URL-адрес, чувствителен к регистру.
Если файл robots.txt не может быть найден в расположении по умолчанию, поисковые системы примут на себя отсутствие директив и просканируют ваш сайт.
Порядок приоритета
Важно отметить, что поисковые системы по-разному обрабатывают файлы robots.txt. По умолчанию первая соответствующая директива всегда побеждает .
Однако с Google и Bing специфичность побеждает . Например: директива Allow побеждает директиву Disallow, если длина ее символа больше.
пример
User-agent: * Разрешить: / about / company / Disallow: / about /
В приведенном выше примере всем поисковым системам, включая Google и Bing, не разрешен доступ к каталогу / about /, кроме подкаталога / about / company /.
пример
User-agent: * Disallow: / about / Allow: / about / company /
В приведенном выше примере всем поисковым системам, кроме Google и Bing , запрещен доступ к каталогу / about /, включая / about / company /.
Google и Bing имеют доступ, потому что директива Allow длиннее директивы Disallow.
Только одна группа директив на одного робота
Вы можете определить только одну группу директив для каждой поисковой системы. Наличие нескольких групп директив для одной поисковой системы приводит их в замешательство.
Будьте максимально конкретны
Директива disallow срабатывает также при частичном совпадении. Будьте максимально точны при определении директивы Disallow, чтобы предотвратить непреднамеренный запрет доступа к файлам.
Пример:
Пользователь-агент: * Disallow: / каталог
Приведенный выше пример не разрешает поисковым системам доступ к:
- / каталог
- / Каталог /
- / Каталог-имя-1
- /directory-name.html
- /directory-name.php
- /directory-name.pdf
Директивы для всех роботов, а также директивы для конкретного робота
Для робота действует только одна группа директив. В случае, если директивы, предназначенные для всех роботов, сопровождаются директивами для конкретного робота, только эти конкретные директивы будут приняты во внимание. Чтобы конкретный робот также следовал директивам для всех роботов, вам необходимо повторить эти директивы для конкретного робота.
Давайте посмотрим на пример, который прояснит это:
пример
Пользовательский агент: * Disallow: / secret / Disallow: / test / Disallow: / еще не запущен / User-agent: googlebot Disallow: / еще не запущен /
В приведенном выше примере всем поисковым системам, кроме Google , не разрешен доступ к / secret /, / test / и / not-launch-while /. Google только не имеет доступа к / еще не запущен /, но разрешен доступ к / secret / и / test /.
Если вы не хотите, чтобы googlebot осуществлял доступ к / secret / и / not-launch-while /, вам необходимо повторить эти директивы специально для googlebot:
Пользовательский агент: * Disallow: / secret / Disallow: / test / Disallow: / еще не запущен / User-agent: googlebot Disallow: / secret / Disallow: / еще не запущен-пока /
Обратите внимание, что ваш файл robots.txt общедоступен. Запрещение разделов сайта там может быть использовано в качестве вектора атаки людьми со злым умыслом.
Файл Robots.txt для каждого (под) домена
Директивы Robots.txt применяются только к (суб) домену, в котором размещен файл.
Примеры
http://example.com/robots.txt действителен для http://example.com, но не для http: // www .example.com или http s : //example.com.
Рекомендуется, чтобы на вашем (суб) домене был доступен только один файл robots.txt, и на ContentKing мы проверили ваш сайт на это. Если у вас есть несколько файлов robots.txt, убедитесь, что они либо возвращают HTTP-статус 404, либо 301-перенаправляют их в канонический файл robots.txt.
Противоречивые рекомендации: robots.txt против Google Search Console
В случае, если ваш файл robots.txt конфликтует с настройками, определенными в консоли поиска Google, Google часто предпочитает использовать настройки, определенные в консоли поиска Google, вместо директив, определенных в файле robots.txt.
Следите за своим файлом robots.txt
Важно отслеживать изменения в файле robots.txt. В ContentKing мы видим много проблем, когда неправильные директивы и внезапные изменения в файле robots.txt вызывают серьезные проблемы с SEO. Это особенно верно при запуске новых функций или нового веб-сайта, подготовленного в тестовой среде, поскольку они часто содержат следующий файл robots.txt:
Пользователь-агент: * Disallow: /
Мы построили robots.txt отслеживание изменений и оповещения по этой причине.
Как вы узнаете, когда ваш robots.txt изменится?
Мы видим это постоянно: файлы robots.txt изменяются без ведома команды цифрового маркетинга. Не будь таким человеком. Начните отслеживать ваш файл robots.txt, теперь получайте оповещения об изменениях!
Не используйте noindex в вашем robots.txt
Хотя некоторые говорят, что это хорошая идея использовать директиву noindex в вашем файле robots.txt, это не официальный стандарт и Google открыто рекомендует не использовать его , Google точно не объяснил, почему, но мы считаем, что мы должны серьезно относиться к их рекомендациям (в данном случае). Это имеет смысл, потому что:
- Трудно отследить, какие страницы должны быть проиндексированы, если вы используете несколько способов подачи сигналов, чтобы не индексировать страницы.
- Директива noindex не является надежной, так как она не является официальным стандартом. Предположим, что Google не будет подписан на 100%.
- Мы знаем, что Google использует директиву noindex, другие поисковые системы не будут использовать ее для страниц noindex.
Лучший способ сообщить поисковым системам, что страницы не должны быть проиндексированы, - это использовать мета-теги роботов или X-роботы-теги , Если вы не можете их использовать, и директива robots.txt noindex является вашим последним средством, чем вы можете попробовать ее, но предположите, что она не будет работать полностью, вы не будете разочарованы.
Примеры файла robots.txt
В этой главе мы рассмотрим широкий спектр примеров файла robots.txt.
Все роботы могут получить доступ ко всему
Существует несколько способов сообщить поисковым системам, что они могут получить доступ ко всем файлам:
Пользователь-агент: * Disallow:
Или с пустым файлом robots.txt или вообще без robots.txt.
Все роботы не имеют доступа
Пользователь-агент: * Disallow: /
Пожалуйста, обратите внимание: один дополнительный символ может иметь все значение.
Все боты Google не имеют доступа
Пользователь-агент: googlebot Disallow: /
Обратите внимание, что при запрете робота Googlebot это относится ко всем роботам Google. Сюда входят роботы Google, которые ищут, например, новости (googlebot-news) и изображения (googlebot-images).
Все боты Google, кроме новостей Googlebot, не имеют доступа
Пользовательский агент: googlebot Disallow: / Пользовательский агент: googlebot-news Disallow:
Googlebot и Slurp не имеют доступа
Пользователь-агент: Slurp Пользователь-агент: googlebot Запретить: /
Все роботы не имеют доступа к двум каталогам
Агент пользователя: * Disallow: / admin / Disallow: / private /
Все роботы не имеют доступа к одному конкретному файлу
Пользователь-агент: * Disallow: /directory/some-pdf.pdf
Робот Google не имеет доступа к / admin /, а Slurp не имеет доступа к / private /
Пользовательский агент: googlebot Disallow: / admin / User-agent: Slurp Disallow: / private /
Robots.txt для WordPress
Файл robots.txt ниже специально оптимизирован для WordPress, предполагая:
- Вы не хотите, чтобы ваш раздел администратора сканировался.
- Вы не хотите сканировать свои страницы результатов внутреннего поиска.
- Вы не хотите сканировать страницы тегов и авторов.
- Вы не хотите, чтобы ваша страница 404 сканировалась.
User-agent: * Disallow: / wp-admin / #block доступ к разделу администратора Disallow: /wp-login.php #block доступ к разделу администратора Disallow: / search / #block доступ к внутренним страницам результатов поиска Disallow: *? S = * #block доступ к страницам результатов внутреннего поиска Disallow: *? p = * #block доступ к страницам, для которых постоянные ссылки не выполняются Disallow: * & p = * #block доступ к страницам, для которых постоянные ссылки не выполняются Disallow: * & preview = * #block access для предварительного просмотра страниц Запретить: / tag / #block доступ к страницам тегов Disallow: / author / #block доступ к страницам авторов Disallow: / 404-error / #block доступ к странице 404 Карта сайта: https://www.example.com/ sitemap_index.xml
Обратите внимание, что этот файл robots.txt будет работать в большинстве случаев, но вы должны всегда корректировать его и проверять, чтобы убедиться, что он соответствует вашей конкретной ситуации.
Каковы ограничения файла robots.txt?
Файл Robots.txt содержит директивы
Несмотря на то, что robots.txt хорошо уважается поисковыми системами, это все же директива, а не мандат.
Страницы, все еще появляющиеся в результатах поиска
Страницы, недоступные для поисковых систем из-за файла robots.txt, но имеющие ссылки на них, могут по-прежнему появляться в результатах поиска, если они связаны с просматриваемой страницы. Пример того, как это выглядит:

Подсказка: можно удалить эти URL-адреса из Google с помощью инструмента удаления URL-адресов Google Search Console. Обратите внимание, что эти URL будут только временно удалены. Чтобы они не попадали на страницы результатов Google, вам необходимо удалять URL-адреса каждые 90 дней.
Кэширование
Google указал, что файл robots.txt обычно кэшируется до 24 часов. Это важно учитывать при внесении изменений в файл robots.txt.
Неясно, как другие поисковые системы работают с кэшированием robots.txt, но в целом лучше избегать кэширования вашего файла robots.txt, чтобы поисковые системы не занимали больше времени, чем нужно, чтобы иметь возможность получать изменения.
Размер файла
Для файлов robots.txt Google в настоящее время поддерживает ограничение размера файла 500 кб. Любой контент после этого максимального размера файла может быть проигнорирован.
Неясно, имеют ли другие поисковые системы максимальный размер файла для файлов robots.txt.
Часто задаваемые вопросы о robots.txt
- Помешает ли использование файла robots.txt поисковым системам показывать запрещенные страницы на страницах результатов поиска?
- Должен ли я быть осторожен с использованием файла robots.txt?
- Незаконно ли игнорировать robots.txt при очистке сайта?
- У меня нет файла robots.txt. Будут ли поисковые системы сканировать мой сайт?
- Могу ли я использовать Noindex вместо Disallow в моем файле robots.txt?
- Какие поисковые системы уважают файл robots.txt?
- Как я могу запретить поисковым системам индексировать страницы результатов поиска на моем сайте WordPress?
1. Помешает ли использование файла robots.txt поисковым системам показывать запрещенные страницы на страницах результатов поиска?
Нет, возьмите этот пример:
Кроме того: если страница запрещена с использованием robots.txt, а сама страница содержит <meta name = "robots" content = "noindex, nofollow">, то роботы поисковых систем будут по-прежнему сохранять страницу в индексе, потому что они никогда не будут узнайте о <meta name = "robots" content = "noindex, nofollow">, так как им не разрешен доступ.
2. Должен ли я быть осторожен с использованием файла robots.txt?
Да, вы должны быть осторожны. Но не бойтесь использовать это. Это отличный инструмент, который поможет поисковым системам лучше сканировать ваш сайт.
3. Является ли незаконным игнорирование файла robots.txt при очистке веб-сайта?
С технической точки зрения нет. Файл robots.txt является необязательной директивой. Мы не можем ничего сказать о том, если с юридической точки зрения.
4. У меня нет файла robots.txt. Будут ли поисковые системы сканировать мой сайт?
Да. Когда поисковая система не обнаружит файл robots.txt в корневом каталоге (в каталоге верхнего уровня хоста), они предположат, что для них нет директив, и попытаются просканировать весь ваш сайт.
5. Могу ли я использовать Noindex вместо Disallow в моем файле robots.txt?
Нет, это не рекомендуется. Google в частности, не рекомендуется использовать директиву noindex в файле robots.txt.
6. Какие поисковые системы уважают файл robots.txt?
Мы знаем, что все основные поисковые системы ниже уважают файл robots.txt:
7. Как я могу запретить поисковым системам индексировать страницы результатов поиска на моем сайте WordPress?
Включение в ваш robots.txt следующих директив запрещает всем поисковым системам индексирование страницы результатов поиска на вашем сайте WordPress, при условии, что не было никаких изменений в функционировании страниц результатов поиска.
Пользовательский агент: * Disallow: /? S = Disallow: / search /
дальнейшее чтение
Похожие
12 инструментов Google Keyword, которые вы можете использоватьИсследование ключевых слов, несомненно, является наиболее важной частью SEO. Прицельтесь на неправильные ключевые слова, и вся ваша кампания облажалась. Оптимизируйте для правильных условий, и вы выиграете джекпот (если, Robots.txt Vs Meta Robots Tag: что лучше?
... доступа сканеров в вашем файле robots.txt. Параметры Robots.txt У вас есть ряд опций, когда дело доходит до вашего robots.txt и что вы хотите, чтобы он содержал, ниже приведены некоторые примеры, которые могут помочь вам создать свой! Чувствительность к регистру Директивы Robots.txt чувствительны к регистру, поэтому, если вы запретите /logo-image.gif, директива заблокирует http://www.domain.com/logo-image.gif, но http://www.domain.com/Logo-Image Что такое SEO? Как это работает?
... некоторые факторы, которые известны в алгоритме трех основных поисковых систем, Google, Yahoo и Bing, которые помогут вам повысить рейтинг: Скорость страницы Мобильные устройства (смартфон, планшет и т. Д.) Дружелюбие Ключевые слова или текст на вашем сайте, адаптированные к вашей отрасли Структура сайта Качество заголовка и описания тегов Качество контента Другие сайты, ссылающиеся на ваш сайт Качество Почему вы не должны использовать мета ключевые слова
... примерно так: Видите ли вы какие-либо потенциальные проблемы, если все это сделали? Почему мета ключевые слова стали неуважительными Не секрет, почему поисковые системы перестали обращать внимание на мета ключевые слова. Это была одна из SEO
SEO (поисковая оптимизация) - это аббревиатура, которая традиционно состоит из двух основных элементов: Естественный или Органический Поиск, и Платный поиск или оплата за клик (PPC) Под естественным поиском понимается естественная индексация веб-сайтов поисковыми системами Плагины WordPress, которые вы должны использовать для SEO
Если вы используете WordPress в качестве своей системы управления контентом и, кстати, это очень хороший выбор в данном случае, вы новичок в веб-дизайне, и в целом вы можете быстро запустить свой веб-сайт, если используете WordPress. Теперь, после создания вашего модно выглядящего веб-сайта, вы поняли, что ваш веб-сайт должен быть в затруднительном положении или мы будем называть его «оптимизированным» и, конечно же, без эффективной оптимизации, в большинстве случаев ваша тяжелая работа Эдинбургская торговая палата »Достаточно ли быстр ваш мобильный сайт для Google?
Google недавно объявил, что новый алгоритм ранжирования по скорости для мобильных поисков будет введен в июле 2018 года. Это изменение будет означать, что время загрузки страниц мобильного веб-сайта станет фактором ранжирования в мобильных поисках. SEO собеседование Вопросы и ответы, которые вы должны знать. Скачать PDF
... несколько вопросов, которые обычно задаются любым интервьюером, если вы собираетесь на собеседование по SEO. Воспользуйтесь этими вопросами в полной мере и получите работу своей мечты SEO. Забудьте, чтобы не дать нам удовольствие. 1. Что вы знаете об обновлениях алгоритма Google? Ответ. Чтобы достойные веб-сайты с лучшим содержанием ранжировались в результатах поиска выше, чем другие, Google постоянно пытается работать над их алгоритмом. Google представил Новый SEO-запуск просмотра Google Analytics
... пример, владельцам магазинов было неясно, пришли ли клиенты на сайт через название бренда, название продукта, приблизительное описание продукта или название магазина. Однако эти данные необходимы для успешной поисковой оптимизации. Данные об органических ключевых словах в Google Analytics все более ограничивались и заменялись примечанием «(не указано)». В настоящее время затронуто до 98 процентов органического трафика. SEO действительно работает?
Обмен - это забота! Во время наших встреч с потенциальными клиентами мы иногда слышим вопрос «Работает ли SEO на самом деле?» От владельцев малого бизнеса до опытных CMO крупных компаний. Это актуальный вопрос, чтобы спросить, сколько людей было продано на мечте о бесконечном бесплатном трафике, в то время как SEO-гуру / ниндзя / рок-звезда разбрасывает жаргон и намекает Мощные методы поисковой оптимизации, которые вы должны использовать
Миллиарды онлайн-пользователей полагаются на поисковые системы, такие как Yahoo, Bing и Google, для получения мгновенной информации. Когда эти пользователи хотят узнать, в каком ресторане подают лучшие блюда итальянской кухни в своем районе, или если они ищут место для следующего путешествия, они могут просто выполнить простой поиск по указанным сайтам. Пользователи онлайн часто нажимают на веб-сайты, которые находятся на вершине. Чем выше рейтинг, тем больше шансов получить больше трафика.
Комментарии
Теперь, когда у вас есть длинный список ключевых слов, как вы узнаете, какие термины выбрать и использовать на вашем сайте?Теперь, когда у вас есть длинный список ключевых слов, как вы узнаете, какие термины выбрать и использовать на вашем сайте? Первая часть головоломки заключается в понимании трех основных типов ключевых слов: короткий, средний и длинный хвост. Ключевые слова с коротким хвостом имеют более высокие объемы поиска, но их очень сложно ранжировать (особенно для новых веб-сайтов). Обычно они состоят из 1-2 слов. Пример «Магазин соков» Ключевые слова Прямо сейчас вы, возможно, спросите, как это влияет на поисковые системы, такие как Google, каков URL страницы?
Прямо сейчас вы, возможно, спросите, как это влияет на поисковые системы, такие как Google, каков URL страницы? Наверняка компьютеру все равно? Ну, вы были бы в некотором роде правы, но дело в том, что наличие ключевых слов, по которым вы пытаетесь ранжироваться в URL страницы, действительно имеет значение. Есть много вещей, которые играют роль в том, как Google определяет рейтинг веб-страницы, и никто не может точно сказать, насколько большую роль играет каждый из этих факторов. Однако Честно говоря, он не выглядит так, как выглядел 15 лет назад , Как сайт с таким сроком все еще имеет значение для SEO сегодня?
Прямо сейчас вы, возможно, спросите, как это влияет на поисковые системы, такие как Google, каков URL страницы? Наверняка компьютеру все равно? Ну, вы были бы в некотором роде правы, но дело в том, что наличие ключевых слов, по которым вы пытаетесь ранжироваться в URL страницы, действительно имеет значение. Есть много вещей, которые играют роль в том, как Google определяет рейтинг веб-страницы, и никто не может точно сказать, насколько большую роль играет каждый из этих факторов. Однако Например, показывает ли ваше исследование поисковых терминов, что целевая группа использует термины, которые еще не были обработаны на сайте?
Например, показывает ли ваше исследование поисковых терминов, что целевая группа использует термины, которые еще не были обработаны на сайте? Тогда вы должны начать работу с новыми текстами. И у вас уже есть страницы с наиболее важными терминами, но вы еще не оценили? Тогда может быть что-то не так с технологией вашего сайта, или авторитет сайта недостаточно высок. В этом случае желательно выбрать другой поисковый запрос. Затем выберите критерий поиска (или, скорее: термины поиска), для которого Как только вы поймете, как важно смотреть на это небольшое пространство, которое суммирует содержимое страницы, вы, вероятно, захотите узнать, как составить отличное мета-описание, верно?
Как только вы поймете, как важно смотреть на это небольшое пространство, которое суммирует содержимое страницы, вы, вероятно, захотите узнать, как составить отличное мета-описание, верно? Каковы уход, советы и лучшие стратегии? Посмотрите следующий ответ на шаг за шагом для этого создания: Честность и объективность Первый шаг в создании мета-описания успеха - быть честным и объективным со своим читателем. Составьте точную сводку того, что у вас Как поисковые системы ранжируют или позиционируют ваш сайт в результатах поиска?
Как поисковые системы ранжируют или позиционируют ваш сайт в результатах поиска? Поисковые системы позиционируют или ранжируют ваши сайты в своих результатах поиска, вычисляя тысячи факторов, используя набор правил. Этот набор правил известен как алгоритм. Каждая поисковая система, такая как Google, Bing и Yahoo, использует уникальный и специфический алгоритм. Вот некоторые факторы, которые известны в алгоритме трех основных поисковых систем, Google, Yahoo и Bing, Есть ли несоответствие между Google Analytics, консолью поиска Google и результатами поиска Google?
Есть ли несоответствие между Google Analytics, консолью поиска Google и результатами поиска Google? Вы можете использовать следующие инструменты для более эффективной оценки и анализа ваших данных: Google Fruition для проверки штрафов барракуда Stat Если ваш рейтинг в Google Analytics, консоли поиска Google и результатах поиска существенно снижается, тектонический сдвиг в алгоритме может иметь место. Рассмотрите возможность Это отличный способ решить, если вы не можете позволить себе таргетировать ключевое слово через PPC, можете ли вы компенсировать потерю трафика через SEO?
Это отличный способ решить, если вы не можете позволить себе таргетировать ключевое слово через PPC, можете ли вы компенсировать потерю трафика через SEO? Добавьте пользовательский отчет по ключевым словам PPC в Google Analytics Пользовательский отчет в социальных сетях Мы видели влияние социальных сетей на SEO, и теперь пришло время убедиться, что мы Вам нужно только протестировать базовую скорость вашего сайта, или вы хотите получить подробные советы о том, как именно повысить скорость вашего сайта?
Вам нужно только протестировать базовую скорость вашего сайта, или вы хотите получить подробные советы о том, как именно повысить скорость вашего сайта? Это определит, какие инструменты могут быть лучше для вас. PageSpeed Insights Если вы ищете бесплатный, простой в использовании инструмент, который может оценить скорость вашего сайта, 5. Что бы вы посоветовали людям сказать своим клиентам, когда клиенты спрашивают их, почему они не занимают первое место в Google, несмотря на то, что занимаются SEO?
5. Что бы вы посоветовали людям сказать своим клиентам, когда клиенты спрашивают их, почему они не занимают первое место в Google, несмотря на то, что занимаются SEO? Я бы порекомендовал ему попросить клиента взглянуть на контент, который ранжируется по первой странице ключевых слов, которые вас интересуют. Представьте себе что-то, что в 10 раз лучше. Создать это. Какие внутренние ресурсы вы должны потратить на кампанию, и что вы будете делать, если у вас нет бюджета?
Какие внутренние ресурсы вы должны потратить на кампанию, и что вы будете делать, если у вас нет бюджета? Если у вас нет бюджета, то я бы порекомендовал вам, чтобы вы обучались. Итак, если у вас есть кто-то, кто отвечает за рекламная рассылка Например, тогда этот человек может начать изучать SEO, чтобы понять основы. У нас есть несколько хороших ресурсов в нижнем колонтитуле нашего веб-сайта в разделе «Изучение
Txt?
Txt работает против вас?
Txt?
Txt изменится?
Txt?
Txt?
Txt при очистке веб-сайта?
Будут ли поисковые системы сканировать мой сайт?
Txt?
Txt?